

To find the best price on market
One of my hobby is to create things for myself. That’s why I have many tools in my workshop including resin printer and FDM printer. It often happens that these devices are not able to print the desired part in sufficient quality. To remedy the problem, I make a mold of the printed part with the help of wax and silicone, and then I pour the part from synthetic resin or other castable resin. Unfortunately, novia‘s webshop displays its prices differently than usual, so I wrote the following web scraper that helps to untangle how much 1 box or kilo of material costs on the company’s webshop, which can later be compared with the price lists of other synthetic resin webshops.
As you can see the product main page shows that 1kg of mold max silicone is 13412 Ft. The uninitiated eye could easily say that this is how much 1 kg of silicone costs at the company.
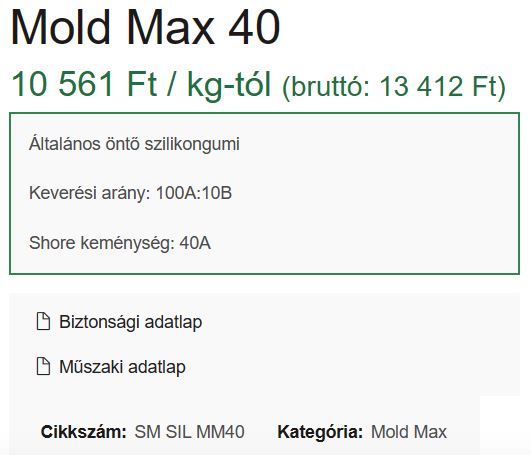
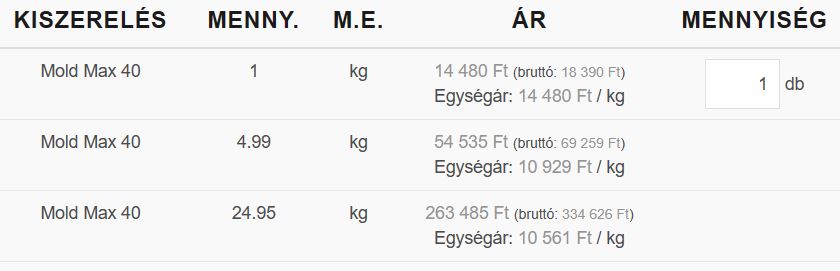
However if you have a closer look a bit under the main infos, there is another price list which contain the real, “not specified for large quantities” price. From here it could turn out that 1kg of mold max 40 silicon price is actually 18390 Ft. This difference is no longer negligible, when someone want to order a kilo of silicone.
In the following script I use selenium and beautifulsoup moduls to parse datas from the website.
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import pandas as pd
import time
from datetime import date as dt
import re
import os
import unicodedata
#%% open webpage
# Main page soup
print('főoldal betöltése')
url = 'https://shop.novia.hu/'
# open webdriver
driver = webdriver.Chrome(r'C:\Chromedriver\chromedriver.exe')
print('driver megnyitás')
driver.get(url)
driver.fullscreen_window()
print('főoldal betöltve')
#%% create df
df = pd.DataFrame(columns = ['termek', 'link'])
#%% scrape menu
soup = BeautifulSoup(driver.page_source,'html.parser')
menu_list = soup.find_all('div', attrs={'class': "basel-navigation"})[2]
menupontok = menu_list.find_all('li')
for menu in menupontok:
for x in menu.find_all('li'):
x.a['href']
x.a.text
df = df.append({'termek' : x.a.text, 'link' : x.a['href']}, ignore_index = True)
#%% menüpontok bejárása, terméklinkek összeszedése
termek_df = pd.DataFrame(columns = ['termek', 'link'])
for link in df.index:
print(df.loc[link, 'link'])
driver.get(df.loc[link, 'link'])
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//div[@class="products elements-grid basel-products-holder basel-spacing- products-spacing- pagination-pagination row grid-columns-4"]')))
soup = BeautifulSoup(driver.page_source,'html.parser')
product_box = soup.find('div', attrs={'data-source': "main_loop"})
products = product_box.find_all('div')
for prod in products:
try:
if len(prod.h3.text) > 1:
print(prod.a['href'])
print(prod.h3.text)
termek_df = termek_df.append({'termek' : prod.h3.text, 'link' : prod.a['href']}, ignore_index = True)
except:
pass
termek_df['termek'] = termek_df['termek'].str.strip()
termek_df.drop_duplicates(subset = ['link'], inplace = True)
termek_df = termek_df.loc[~termek_df['link'].str.contains("termekkategoria")]
termek_df.reset_index(drop = True, inplace = True)
#%% termekbejaras
termek_arral_df = pd.DataFrame(columns = ['termek', 'link', 'short_descp', 'kiszereles',
'mennyyiseg', 'mertekegyseg', 'ar'])
for i in termek_df.index:
# i = 160
termek_link = termek_df.loc[i, 'link']
termek_nev = termek_df.loc[i, 'termek']
driver.get(termek_link)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//h1[@class="product_title entry-title"]')))
soup = BeautifulSoup(driver.page_source,'html.parser')
print(str(i))
print(termek_nev)
print(termek_link)
try:
short_descp = unicodedata.normalize("NFKD", soup.find('div', attrs={'class': "woocommerce-product-details__short-description"}).text.strip()).replace('\n', ' ')
except:
short_descp = ''
print(short_descp)
tablazat = soup.find('div', attrs={'class': "col-sm-12 product-tabs-wrapper"})
tablazat = soup.find('table')
if tablazat != None:
for x in list(range(0,len(tablazat.tbody.find_all('tr')))):
print(x)
try:
subnev = tablazat.tbody.find_all('tr')[x].find('td', attrs={'class': "optionscol attribute_pa_kiszereles"}).text
mertekegyseg = tablazat.tbody.find_all('tr')[x].find('td', attrs={'class': "optionscol quantity_unit"}).text
try:
kiszereles = float(tablazat.tbody.find_all('tr')[x].find('td', attrs={'class': "optionscol quantity_unit_value"}).text)
except:
kiszereles = 0
ar = float(unicodedata.normalize("NFKD",(tablazat.tbody.find_all('tr')[x].find('small', attrs={'class': "woocommerce-price-suffix"}).span.text)).split(' Ft')[0].replace(' ', ''))
print('subnev = {}, \nár = {} \n '.format(subnev, ar))
termek_arral_df = termek_arral_df.append({'termek' : termek_nev,
'link' : termek_link,
'short_descp': short_descp,
'kiszereles' : subnev,
'mennyyiseg' : kiszereles,
'mertekegyseg' : mertekegyseg,
'ar': ar}, ignore_index = True)
except:
pass
#%% export
termek_arral_df.to_excel(r'C:\novia_arlista.xlsx')